
.webp)
CMS was explicit about the goals of TiC 2.0: reduce duplication, normalize file structure, and make machine-readable files more usable at scale.
One month in, we’re seeing meaningful progress—and some familiar patterns of “compliance in name only.”
Across the networks we track, we’re seeing:
- ~87% adoption of version 2.0 in the first month.
- Compressed file sizes are down ~35% overall.
- That’s over 200GB per month eliminated from transfer and storage, and more than 1.4TB of uncompressed data removed from processing.
- Effective record counts actually increased 35%, likely due to side effects of new schema fields like business_name and network_name.
- We’re able to rely on usable TIN labels from at least one payer.
That’s real progress! But as always with TiC, the details matter. In this edition of MRF Processing Notes, I’ll break down the adoption of 2.0 and where it’s helping (or hurting) the cause of usable transparency data.
Schema 2.0 Adoption Rates
We analyzed the 291 different payer / plan networks in our inventory with postings between February 1st and February 15th, and looked at the reported schema versions in the header. Here’s a breakdown of distinct version strings we see:
Count Percent Version
----- ------- -------------------
130 44.67% 2.0.0
38 13.06% 1.3.1
28 9.62% 1.0.0
25 8.60% (no version found)
21 7.22% 1.6.1
10 3.44% 1.2.0
8 2.75% 1.6.0
7 2.41% 1.1.0
7 2.41% 1.0.7
4 1.37% 2.1.0
3 1.03% 1.6.2
3 1.03% v2.0.0
2 0.69% V2.0.0
2 0.69% 2.1
1 0.34% 2.0.328
1 0.34% v2.0.1
1 0.34% 2.0.1
By these metrics, approximately 50% of payers complied in February. Honestly? That’s better than I expected!
It was pointed out to me that technically, the 2.0 effective date was February 2nd since the 1st was a holiday. Which means, anyone who posted version 1.0 files on 2/1 were still technically compliant in doing so. If we use 2/2 as the cutoff date and recut the data, the compliance rate rises to 86.6%.
It is left to be seen whether the 2/1 postings update in 3/1, so in a few weeks we’ll report back with an update.
Field-Level Adoption: The Real Story
Of course, labeling a file “2.0” and actually implementing 2.0 are two different things. We’ve seen varying levels of actual schema compliance at a field level from folks posting 1.0 files for years, so we asked ourselves, if we dive one level deeper, how completely are folks adopting the changeset?
Here’s what we’re seeing from the networks ingested so far:
Version String vs. V2.0 Fields Matrix
Reported Version Has V2 Fields No V2 Fields Total
------------------ ------------------ ------------------ ------------------
v1.x 4 (1.37%) 118 (40.55%) 122 (41.92%)
v2.x 142 (48.80%) 2 (0.69%) 144 (49.48%)
Unknown / Missing 6 (2.06%) 19 (6.53%) 25 (8.59%)
TOTAL 152 (52.23%) 139 (47.77%) 291 (100%)
One fun finding here that every data engineer and/or MRF processor already knows - header values and version strings aren’t always updated in agreement with file contents. Some V1 labeled files have v2 fields, some v2 labels are missing those fields, and many files are unlabeled and wind up going either way. Just because some of the market has adopted 2.0, you can’t throw away your older parsing code and handlers just yet.
One note where I am really happy is that all 2.0 adopters so far appear to have dropped ‘remote’ provider reference lookups, where the provider_reference is a URL instead of the actual data. We’ve found that to be a primary cause of fragility and unusable data when the URLs expire or are misaligned, and we’re happy to see that gone.
For our customers, the most important takeaway from all of this is that Serif Health manages all this annoyance and complexity for you - we map both versions down to a single, consistent schema so you don’t have extra data work to do regardless of the raw format.
The Blues: Where 2.0 Really Worked
The biggest wins came from Blues plans, where entities were repeating provider group lists inline on every rate record, for every code × rate pair. That duplication is explicitly disallowed in 2.0, in favor of moving the provider groups to a single reference at the top of the file.
As you can imagine, not repeating the data over and over has substantial impacts on file sizes.
Example: Horizon BCBS
- 97% reduction in file sizes (43.5GB -> 1.0GB for PPO, 6GB->99MB for AEPO)
- With only an 8% reduction observed in record count (likely due to an unrelated reduction in codes covered)
Other Blues adopting the backref structure:
- Blue Cross and Blue Shield of Kansas
- Blue Cross and Blue Shield of Vermont
- Blue Cross and Blue Shield of Wyoming
- Blue Cross Blue Shield Louisiana
- Blue Cross Blue Shield of Massachusetts
- Blue Cross Blue Shield of Michigan
- Blue Cross Blue Shield of Rhode Island
- Blue Cross of Idaho
If we look only at these individual Blues:
- 91.5% compressed file size reduction
- ~161GB per month eliminated
If we include the Blue Card set (which aggregates across Blues nationwide):
- One Blue Card cross-cutting network fileset alone dropped over 100GB compressed (~66% reduction) while record count actually increased 89% to 47 billion records
- Double-counting included, total reduction hits:
- 79% compressed reduction
- ~265GB per month
One note: we saw 12% fewer Blue Card files this month referenced in the index than last, which is… interesting. This appears to be a side effect of compression, but we’ll keep digging in.
Overall, these metrics demonstrate some wins for TiC 2.0 making file sizes smaller.
Aetna: Wins on Size, Loss on Usability
In addition to adopting the various new 2.0 schema keys, Aetna made two meaningful changes that decreased their file sizes:
- Adopted the CSTM-00 place of service code, which removed tons of redundant long string values previously listing every available place of service value.
- Removed a significant quantity of ICD codes from their rate files.
Net Impact:
- ~37% compressed file size reduction
- ~62% uncompressed file size reduction
That’s substantial…but they adopted a problematic pattern in their provider groups and business_name labels that actually appears to have added significant bloat to record counts and ambiguity.
Namely, they are splitting groups apart with repeated NPI list subsets, and attaching business_name labels for NPIs instead of labelling the subentity with an actual, common business name connected to the EIN.
To make this crystal clear, here’s a screenshotted example from one of their recent Open Access Elect Choice fully insured postings:
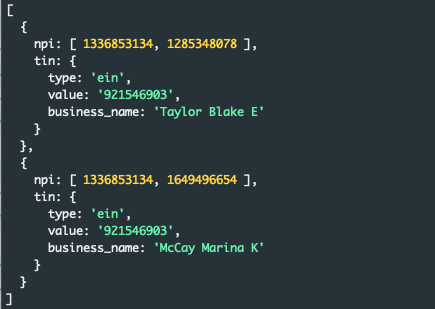
As you can see, the two npi lists in this group have a common Type 2 NPI - 1336853134, which is the NPI for REVIVE CHIROPRACTIC LLC. That seems like an obvious, better choice for the business_name field, right? And a consistent one to apply across the group?
Problematically, choosing to use the Type 1 here as a label means the user of this data has no meaningful business name and now will wind up creating *two* records; one for each subgroup, every time this group is referenced, each attached to the same rates. If you’re looking for the NPI1, you’d only get one of those records, but for a consumer of the data who wants to understand Revive Chiropractic’s rate structure and either searches their EIN or the NPI2, you’re getting two records back.
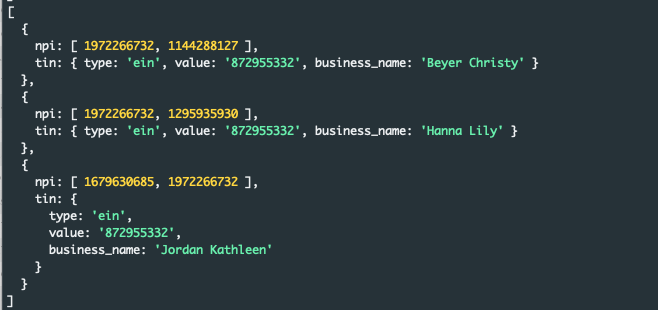
You can imagine how this gets more difficult as the provider count grows, below to three providers:
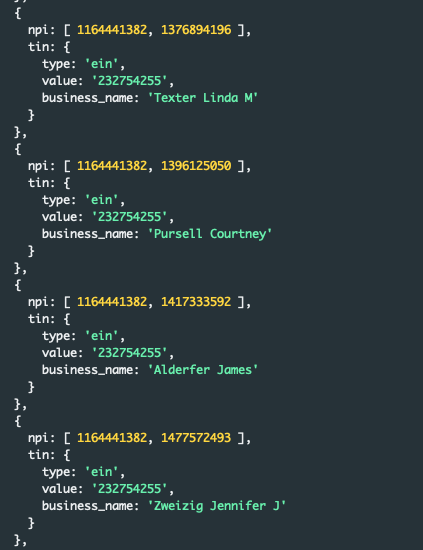
Or four:
Or beyond:
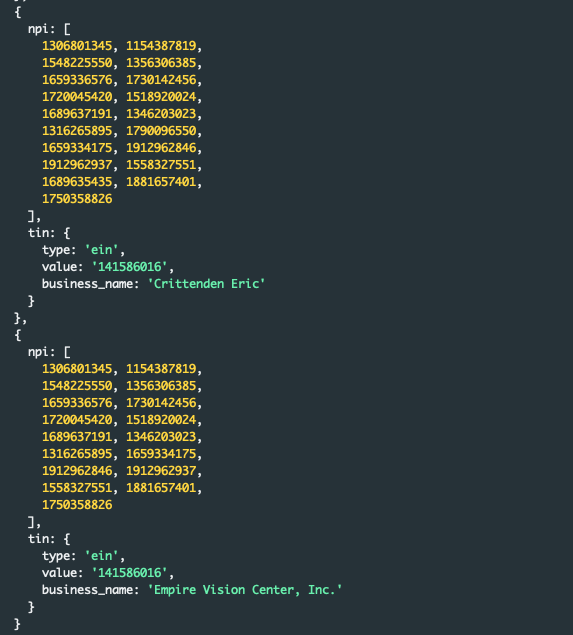
This last example is interesting as many groups have actually enumerated a type 2 business name as one of the options in the group - but identifying which is the actual business name requires all the same work of external joining to datasets this business_name field was intended to alleviate.
The net result? Near tripling of effective rate counts after reference expansion - to over 200 billion records in just one posting. So while file sizes shrank structurally, rate multiplicity increased materially. And the takeaway for users of the data is that you fundamentally shouldn’t rely on Aetna’s adoption of the business_name field to answer questions about entity resolution.
I’d be remiss if I didn’t point to the CMS implementation guide section on this field, and point out that it clearly says the label should be populated with “The common business name that is associated with the EIN reported for the value attribute”. Like many other instances we’ve catalogued of schema misuse, this reporting pattern complies structurally but introduces semantic duplication and reduces usability of the data - hopefully CMS can issue further guidance to clarify this wasn’t the intention of the field.
We have a few tricks up our sleeve here - we won’t be trusting these raw labels directly, we’ll be inferring and probabilistically picking the best name option for an EIN across all the data we see. So that means our customers won’t be getting bit by this Aetna issue.
The Counterexample: UnitedHealthcare
UnitedHealthcare’s files were already fairly optimized. The addition of long strings and new keys for TiC 2.0 appear to have increased file size by about 30%.
While this hurts the overall “file size reduction” narrative of TiC 2.0, the value of the new fields materially improves provider-level clarity and disambiguation. Previously we were unable to label more than ~62% of United’s TINs with entity name values - we expect having clear, accurate labels covering all of the data will be a big win for our customers. In this case, I believe the increase likely improves downstream usability enough to justify the cost.
Not all increases are bad!
Anthem: When network_name Goes Off the Rails
TiC 2.0 also introduced network_name to normalize and reduce duplication; the idea being that common sets of providers form networks and contracted rate schedules that are often shared across many different plan designs. In real-world terms, few providers contract rates at a product or plan level - they sign one network-level contract and that rate applies across all the products that use that backing network.
We are advocates of this concept, and even signed a RFI comment letter advocating for it. The theory was that by specifying a network_name, the block and references could be shared and re-used across plans relying on the common network entity.
So far, it looks like no one is trying to use the field to reduce duplication or create sets of coalesced networked providers. Instead, most seem to have bulk copied long, permuted plan_name strings from their ToC into the network_name field for every provider group.
For just one Anthem Kentucky file, we observed 63 permutations of essentially the same comma-delimited string of networks applied to a single provider ein / npi_list pair:
Pathway HMO POS,Blue Next PCP Copay,Member tier Product OT KY,Blue Access Network Norton Blue Access,Pathway X Tiered Hospital,Blue Next Member tier,Pathway,Anthem HealthSync,Pathway Transition HMO OFF Exchnage,Bon Secours Mercy Health - Tier 1,Workers Comp Kentucky Worker Comp.,Kentucky Exchange PPO HIX,Blue Access,IU Health Premier Network Tier 1,Member tier Product PT KY,Pathway Tiered Hospital,Workers Comp IN KY,Univ of KY-RHP-Blue Access in KY WGS,Blue Priority Plus Co Pay RHC,Indiana Exchange HIX,Blue Access Options PPO for ERC Health,Blue Access PPO,Blue Access Options PPO,IU Health Narrow Network Tier 1,Pathway X Transition HMO ON Exchange,Appalachian Regional Healthcare,Green Network,Access Network for NetworX Blue Access,Blue Priority Plus using PPO- apply PCP Office Copay,Pathway X
As you can see, these “networks” do include some network-like designations (tiers, regionality, etc.) but much more frequently are product / class / benefit design tags and non-human-readable acronyms.
I don’t doubt that Anthem could actually have 63 different network designs effective in Kentucky that apply to the specific provider group I pulled this from, but in no way is this information being used to organize or deduplicate the information for MRF consumers.
This feels like compliance in name only, and a big missed opportunity to structurally refactor the files to reduce bloat.
The Net Impact of TiC 2.0
Across the inventoried networks we tracked so far:
- Depending on how you slice it, at least half or most of the market adopted 2.0 within the first month; we’ll need to wait until 3/2 to know for sure
- ~40% reduction in compressed file size, meaning over 200GB per month in compressed transfer and storage saved and over 1.4TB reduction in uncompressed bytes processed
- A net increase in rate record counts of ~30%, not all of it valuable new information
- Thankfully, usable business names for hard-to-label TINs from payers like United will make deliveries cleaner and more identifiable for our customers
- Jury is still out on the utility of network_name - we’ll keep tabs on it and dive into details on a future post
As usual in our space, CMS will likely have more work to do on GitHub to help implementers adopt the spirit of the law, not just the letter of it. Thankfully, the takeaway here is net positive – thanks to the size improvements and business_name labels, TiC 2.0 is looking like a meaningful step forward for data usability. If you’re one of our data consumers, rest assured we’ll be managing any turbulence here, and you can expect to see newly available fields and more complete TIN labels in our data starting with our March deliveries.
As always, if you’re interested in our expertise working with transparency data, get in touch!